AniTalker-Digital Human Solution Sound-driven portrait generation of vivid and diverse head talking video algorithm analysis
2. AniTalker
AniTalker represents a technological innovation that breaks traditional boundaries and transforms static portrait photos into dynamic digital avatars. The following are refinements and additions to your description of AniTalker’s features:
Technical Innovation : AniTalker uses advanced artificial intelligence technology to enable static images to talk and change expressions naturally and fluently according to voice commands.
Dynamic Avatar : This technology can transform ordinary photos into digital avatars with rich expressions and movements, bringing users an unprecedented interactive experience.
Self-supervised learning : AniTalker uses self-supervised learning, a cutting-edge machine learning strategy, which enables the model to autonomously learn and understand the complexity of human face dynamics without relying on cumbersome labeled data.
Natural Expression : Compared with early digital humans, the animations generated by AniTalker are no longer limited to preset action templates and can show more natural and realistic facial expressions.
Flexibility : AniTalker’s self-supervised learning method gives the model a strong generalization ability, enabling it to adapt to a variety of different voices and expressions, thereby creating more diverse and personalized animation effects .
Innovative Applications : This technology has broad application prospects. It can be used not only in entertainment and social media, but also in education, training, customer service and other fields, providing new possibilities for digital content creation and human-computer interaction.
Easy to use : AniTalker’s design philosophy is to simplify the animation process, making it more accessible and easy to use, so that users without professional animation background can easily create high-quality animated videos.
2.1 Effects achieved by AniTalker
Facial animation generation: AniTalker can transform static portrait photos and audio signals into vivid speaking facial animations. This not only covers accurate lip sync, but also includes facial expressions and head movements that perfectly match the speech content, providing the audience with a brand new communication experience.
Diversity and controllability: Users can adjust input and parameter settings according to different needs to generate a series of facial animations with rich expressions and different movements. This high degree of customization enables AniTalker to meet a variety of needs from entertainment to professional applications.
Realism and dynamic performance: AniTalker is good at capturing subtle facial dynamics, including complex non-verbal information such as blinking and smiling. The precise reproduction of these details greatly enhances the realism and expressiveness of the animation.
Long video generation capability: The technology is not limited to the generation of short clips, but can also produce long facial animation videos of more than 3 minutes. This makes AniTalker very suitable for virtual assistants, digital character performances, and other application scenarios that require long-form animated content.
Like a meticulous observer, AniTalker extracts the subtleties of every smile, wink, and nod from a large number of portraits and video clips and converts them into a sophisticated “expression movement code”.

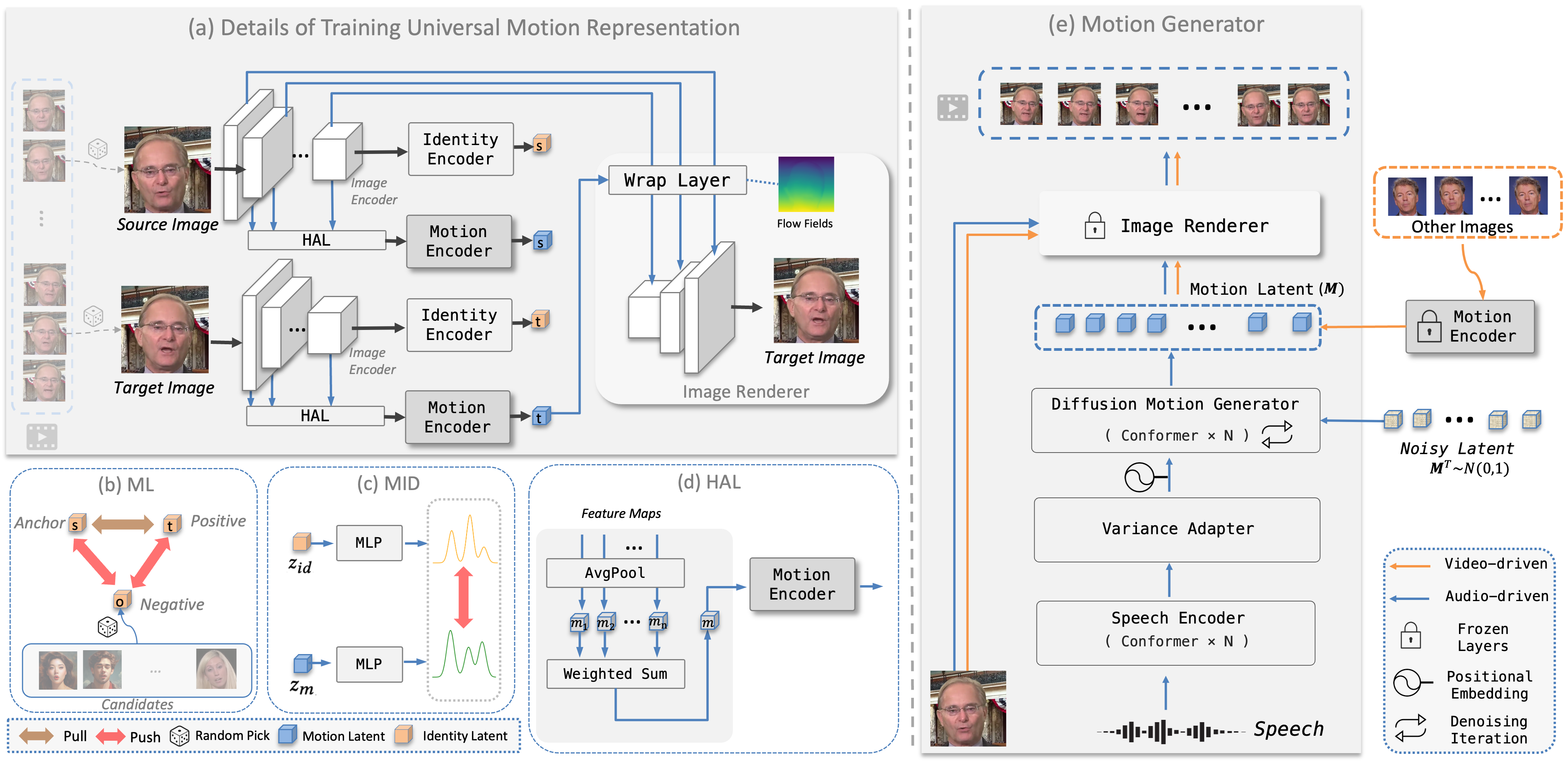
The details of the identity and motion encoders, as well as how the Hierarchical Aggregation Layer (HAL) works, are shown below:

More importantly, AniTalker has cleverly achieved the separation of “person identity” and “motion performance”. It not only uses “identity recognition technology” to distinguish the uniqueness of different people, but also uses “identity and motion separation technology” to ensure that while capturing the action, no identity features are mixed in, ensuring the universality of the action and maintaining the original appearance of the portrait.
In order to make the digital human’s movements more diverse and natural, AniTalker introduced the “motion control function”. This technology cleverly adds fine-tuning to the basic motion framework, making the final animation effect both natural and smooth and full of personality. At the same time, AniTalker can also finely control each movement and expression of the digital human according to instructions, just like a director accurately controlling the performance of an actor.

These rich experimental results confirm the powerful effect of AniTalker. The digital people created not only have natural expressions and coherent movements, but also have strong adaptability. They can perfectly adapt to real people as well as cartoons, sculptures and other styles, demonstrating its excellent versatility.
Motion manifold in continuous motion space:

3. Project deployment
Environment creation:
git clone https://github.com/X-LANCE/AniTalker.git
cd AniTalker
conda create -n anitalker python==3.9.0
conda activate anitalker
conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cudatoolkit=11.1 -c pytorch -c conda-forge
pip install -r requirements.txt
Demo1:
Keep pose_yaw, pose_pitch, pose_roll to zero.
python ./code/demo_audio_generation.py \
--infer_type 'mfcc_pose_only' \
--stage1_checkpoint_path 'ckpts/stage1.ckpt' \
--stage2_checkpoint_path 'ckpts/stage2_pose_only.ckpt' \
--test_image_path 'test_demos/portraits/monalisa.jpg' \
--test_audio_path 'test_demos/audios/english_female.wav' \
--result_path 'results/monalisa_case1/' \
--control_flag True \
--seed 0 \
--pose_yaw 0 \
--pose_pitch 0 \
--pose_roll 0
Demo2:
Changing pose_yaw from 0 to 0.25
python ./code/demo.py \
--infer_type 'mfcc_pose_only' \
--stage1_checkpoint_path 'ckpts/stage1.ckpt' \
--stage2_checkpoint_path 'ckpts/stage2_pose_only.ckpt' \
--test_image_path 'test_demos/portraits/monalisa.jpg' \
--test_audio_path 'test_demos/audios/english_female.wav' \
--result_path 'results/monalisa_case2/' \
--control_flag True \
--seed 0 \
--pose_yaw 0.25 \
--pose_pitch 0 \
--pose_roll 0
Demo3:
Talking in Free-style
python ./code/demo.py \
--infer_type 'mfcc_pose_only' \
--stage1_checkpoint_path 'ckpts/stage1.ckpt' \
--stage2_checkpoint_path 'ckpts/stage2_pose_only.ckpt' \
--test_image_path 'test_demos/portraits/monalisa.jpg' \
--test_audio_path 'test_demos/audios/english_female.wav' \
--result_path 'results/monalisa_case3/'